

“Đã lập chỉ mục, mặc dù bị chặn bởi robots.txt” hiển thị trong Google Search Console (GSC) khi Google đã lập chỉ mục các URL mà họ không được phép thu thập thông tin.
Trong phần lớn các trường hợp, đây sẽ là một vấn đề đơn giản mà bạn đã chặn thu thập thông tin trong tệp robots.txt của mình. Tuy nhiên, có một số điều kiện bổ sung có thể gây ra sự cố, vì vậy chúng ta hãy thực hiện quy trình khắc phục sự cố sau để chẩn đoán và khắc phục mọi thứ hiệu quả nhất có thể:
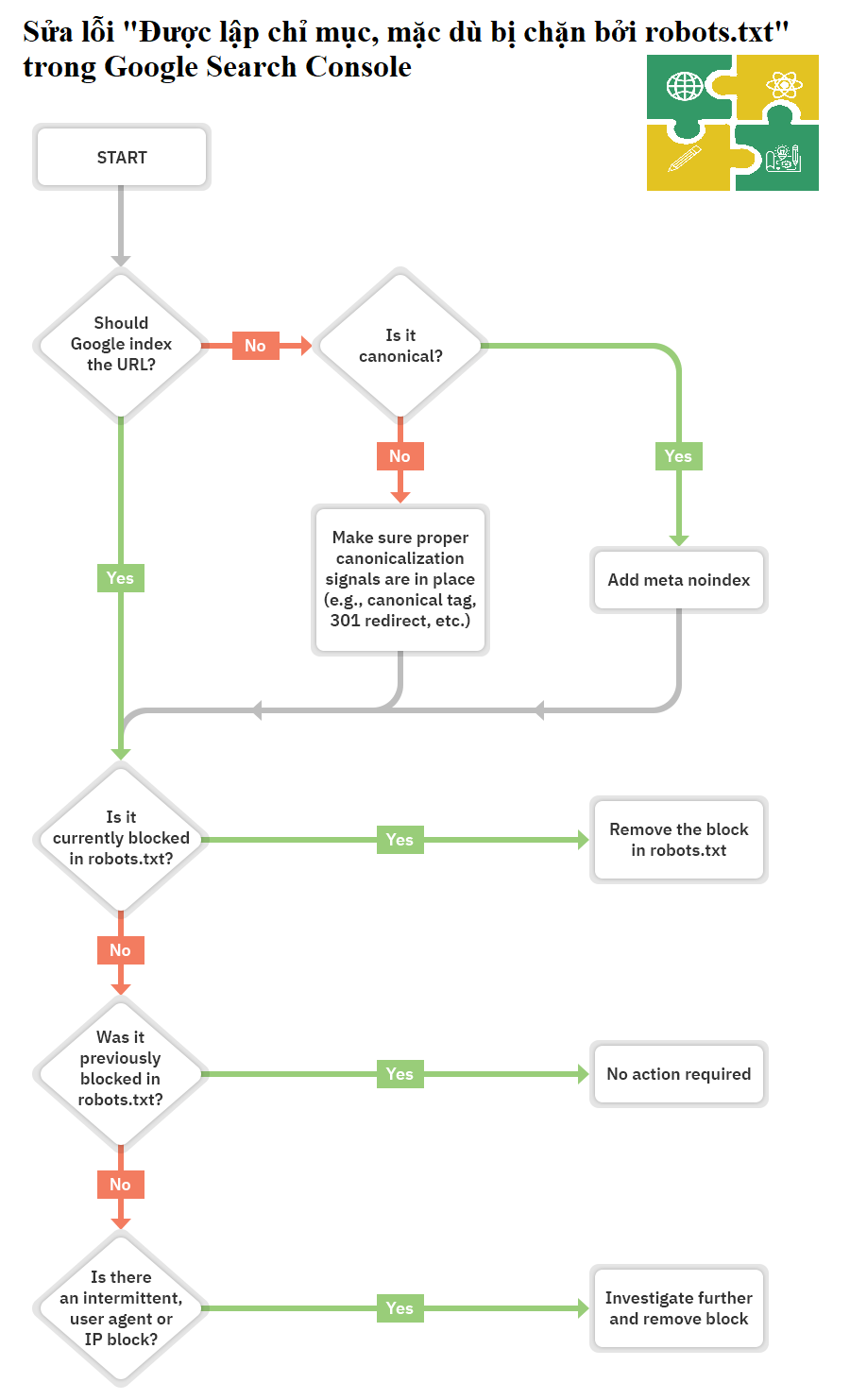
Vậy nên bước đầu tiên là tự hỏi bản thân xem bạn có muốn Google lập chỉ mục URL ?
Nếu bạn không muốn URL đã lập chỉ mục
Chỉ cần thêm thẻ meta robot ngăn lập chỉ mục (noindex meta robots) và đảm bảo cho phép thu thập thông tin.
<meta name="robots" content="noindex" />Nếu bạn chặn thu thập thông tin một trang, Google vẫn có thể lập chỉ mục trang đó vì thu thập thông tin và lập chỉ mục là hai việc khác nhau. Trừ khi Google có thể thu thập dữ liệu một trang, họ sẽ không nhìn thấy thẻ meta ngăn lập chỉ mục và vẫn có thể lập chỉ mục trang vì nó có liên kết.
Nếu URL chuẩn hóa cho một trang khác, không thêm thẻ meta robot ngăn lập chỉ mục. Chỉ cần đảm bảo có các tín hiệu chuẩn hóa phù hợp, bao gồm cả thẻ chuẩn trên trang chuẩn và cho phép thu thập thông tin để các tín hiệu đi qua và hợp nhất một cách chính xác. Ví dụ :
<link rel=“canonical” href=“https://example.com/sample-page/” />Nếu bạn muốn URL đã lập chỉ mục
Bạn cần tìm ra lý do tại sao Google không thể thu thập thông tin URL và loại bỏ khối.
Nguyên nhân rất có thể là do khối thu thập thông tin trong robots.txt. Nhưng có một số trường hợp khác mà bạn có thể thấy thông báo cho biết rằng bạn bị chặn. Hãy xem qua những thứ này theo thứ tự mà bạn có thể nên tìm kiếm chúng.
- Kiểm tra thu thập thông tin trong robots.txt
- Kiểm tra các trường hợp ngắt quãng
- Kiểm tra trường hợp là tác nhân người dùng là tổ chức
- Kiểm tra trường hợp là IP
1. Kiểm tra thu thập thông tin trong robots.txt
Cách dễ nhất để xem vấn đề là với trình kiểm tra robots.txt trong GSC, sẽ thấy được những URL đã gửi bị chặn bởi robots.txt.
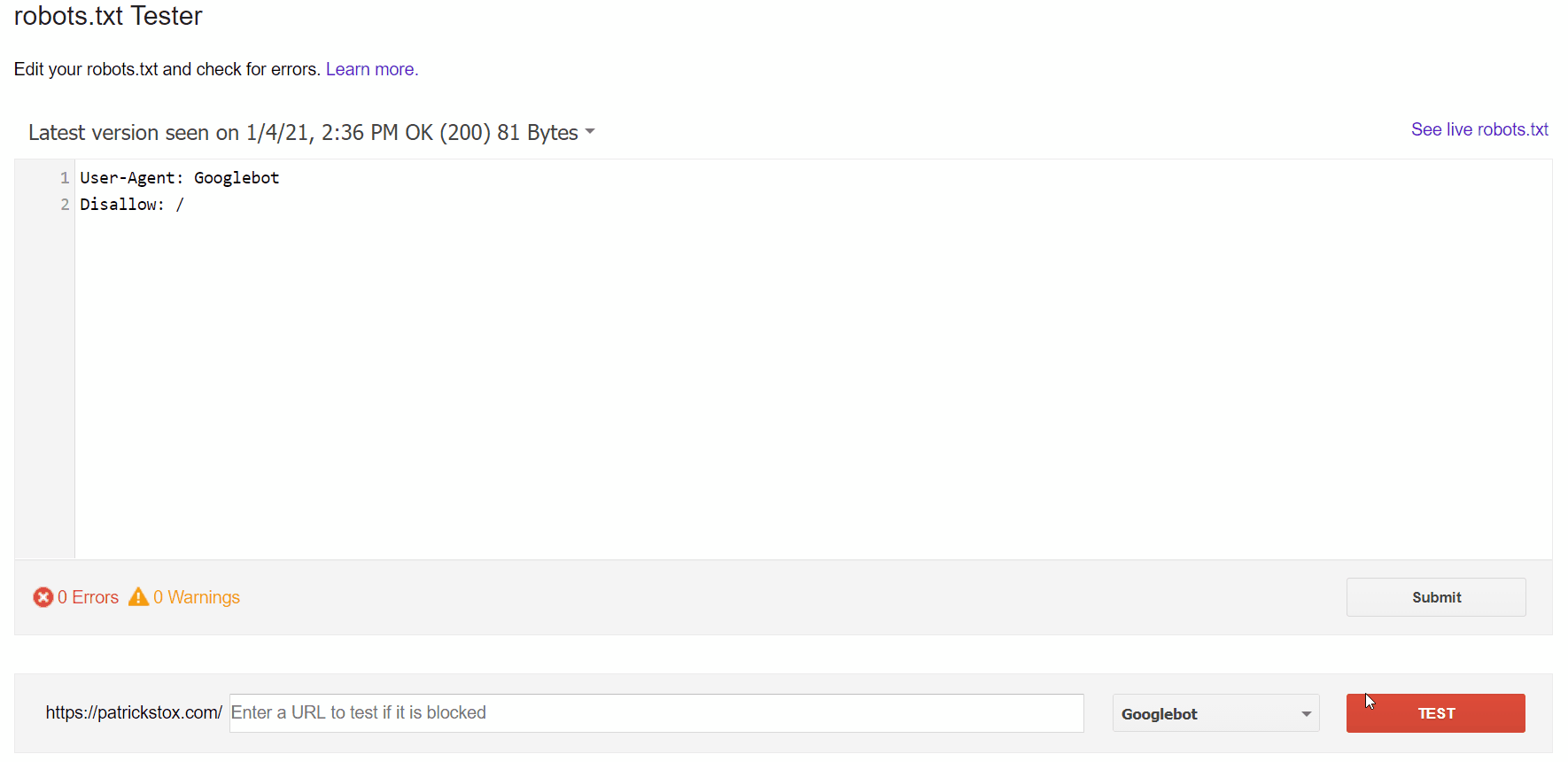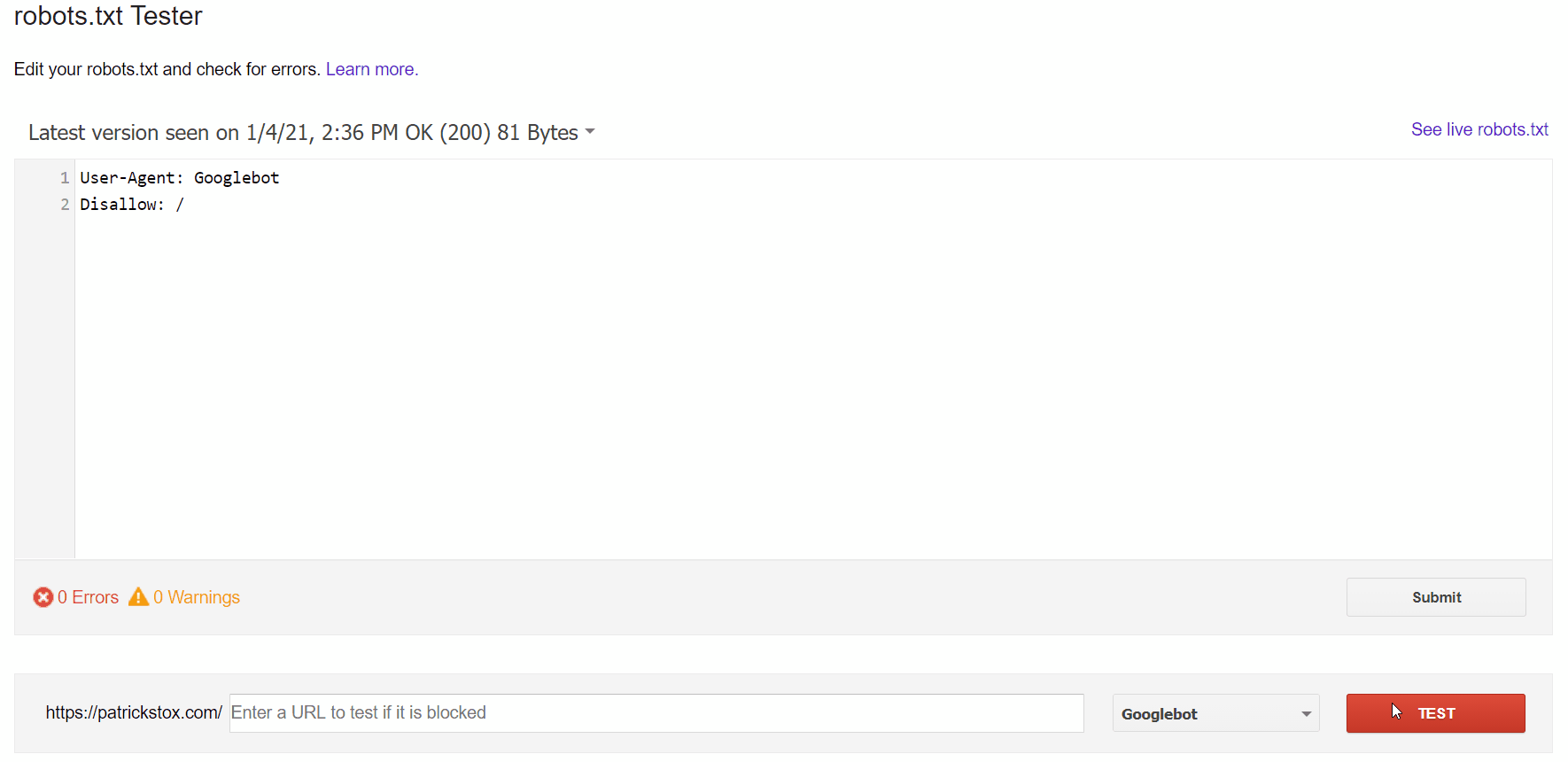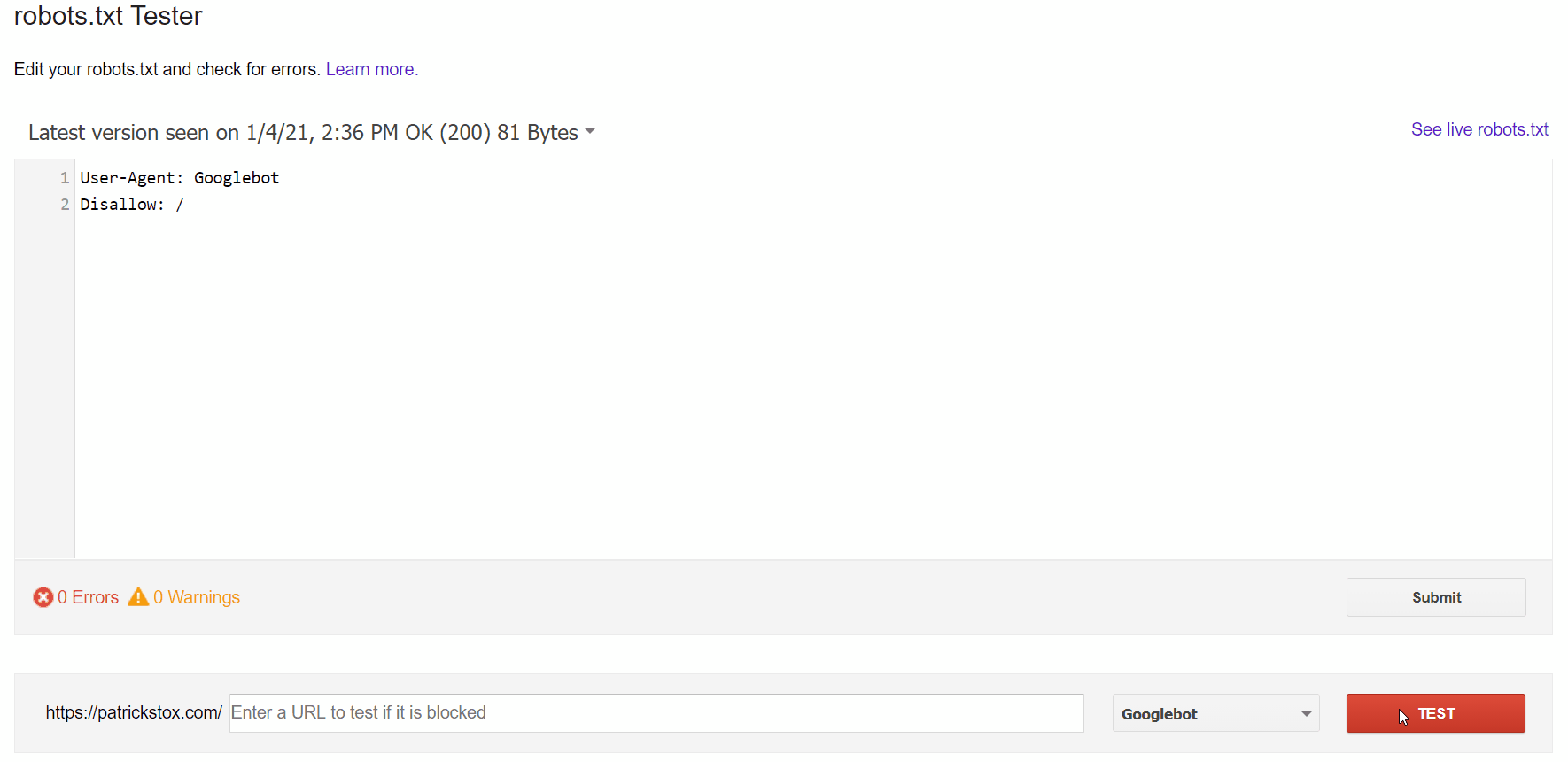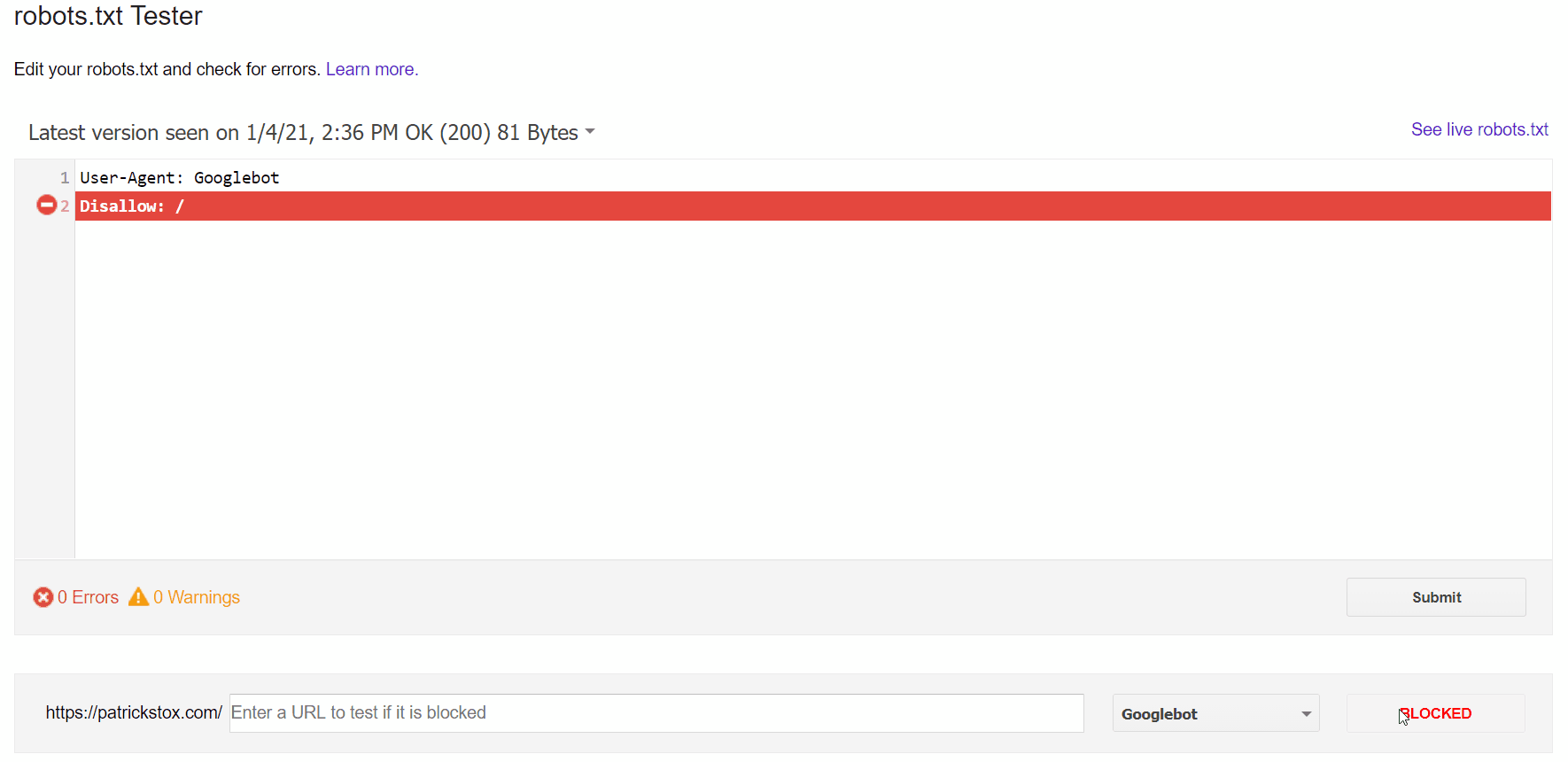
Nếu bạn biết mình đang tìm gì hoặc bạn không có quyền truy cập GSC, bạn có thể điều hướng đến domain.com/robots.txt để tìm tệp. Chúng ta có thể xem thêm thông tin trong bài viết robots.txt của mình, nhưng bạn có thể đang tìm kiếm một tuyên bố không cho phép như:
Disallow: /Có thể có một tác nhân người dùng cụ thể được đề cập hoặc nó có thể chặn tất cả mọi người. Nếu trang web của bạn là mới hoặc đã ra mắt gần đây, bạn có thể muốn tìm tất cả:
User-agent: *
Disallow: /Nếu bạn không tìm thấy sự cố?
Có thể ai đó đã sửa khối robots.txt và giải quyết vấn đề trước khi bạn xem xét vấn đề. Đó là tình huống tốt nhất. Tuy nhiên, nếu sự cố dường như đã được giải quyết nhưng lại xuất hiện ngay sau đó, bạn có thể bị chặn không liên tục.
Vậy ta phải làm thế nào để khắc phục ?
Bạn sẽ muốn xóa câu lệnh disallow gây ra lỗi. Cách bạn thực hiện việc này khác nhau tùy thuộc vào công nghệ bạn đang sử dụng.
Nếu là WordPress
Nếu sự cố ảnh hưởng đến toàn bộ trang web của bạn, thì nguyên nhân rất có thể là bạn đã kiểm tra cài đặt trong WordPress để không cho phép lập chỉ mục. Lỗi này thường gặp trên các trang web mới và sau khi di chuyển trang web. Làm theo các bước sau để kiểm tra nó:
B1: Nhấp vào ‘Cài đặt’
B2: Nhấp vào ‘Đọc’
B3: Đảm bảo rằng ‘Hiển thị với công cụ tìm kiếm’ được bỏ chọn.
Nếu là WordPress với Yoast
Nếu bạn đang sử dụng Yoast SEO plugin, bạn có thể chỉnh sửa trực tiếp tệp robots.txt để xóa câu lệnh chặn.
B1: Nhấp vào ‘Yoast SEO‘
B2: Nhấp vào ‘Công cụ’
B3: Nhấp vào ‘Trình chỉnh sửa tệp’
Nếu là WordPress với Rank Math
Tương tự như Yoast, Rank Math cho phép bạn chỉnh sửa trực tiếp tệp robots.txt.
B1: Nhấp vào ‘Rank Math'
B2: Nhấp vào ‘Cài đặt chung’
B3: Nhấp vào ‘Chỉnh sửa robots.txt’
Hoặc sử dụng FTP
Nếu bạn có FTP truy cập vào trang web, bạn có thể trực tiếp chỉnh sửa tệp robots.txt để loại bỏ tuyên bố không cho phép gây ra sự cố. Nhà cung cấp dịch vụ lưu trữ của bạn cũng có thể cấp cho bạn quyền truy cập vào Trình quản lý tệp cho phép bạn truy cập trực tiếp vào tệp robots.txt.
2. Kiểm tra các trường hợp ngắt quãng
Sự cố gián đoạn có thể khó khắc phục hơn vì không phải lúc nào các điều kiện gây ra khối cũng có mặt.
Điều tôi khuyên bạn nên kiểm tra lịch sử tệp robots.txt của bạn.
Ví dụ, trong GSC trình kiểm tra robots.txt, nếu bạn nhấp vào menu thả xuống, bạn sẽ thấy các phiên bản trước đây của tệp mà bạn có thể nhấp vào và xem chúng chứa những gì.
Wayback Machine trên archive.org cũng có lịch sử của các tệp robots.txt cho các trang web mà chúng thu thập thông tin. Bạn có thể nhấp vào bất kỳ ngày nào mà họ có dữ liệu và xem tệp bao gồm những gì vào ngày cụ thể đó.
Làm thế nào để khắc phục ?
Quá trình khắc phục các lỗi gián đoạn sẽ phụ thuộc vào nguyên nhân gây ra sự cố.
Ví dụ, một nguyên nhân có thể xảy ra là bộ nhớ đệm được chia sẻ giữa môi trường thử nghiệm và môi trường trực tiếp. Khi bộ đệm ẩn từ môi trường thử nghiệm đang hoạt động, tệp robots.txt có thể bao gồm lệnh chặn. Và khi bộ nhớ cache từ môi trường trực tiếp hoạt động, trang web có thể thu thập dữ liệu được. Trong trường hợp này, bạn muốn tách bộ nhớ cache hoặc có thể loại trừ các tệp .txt khỏi bộ nhớ cache trong môi trường thử nghiệm.
3. Kiểm tra các lỗi là tác nhân người dùng tổ chức (User Agent)
Chặn tác nhân User Agent là khi một trang web chặn các tác nhân người dùng cụ thể như Googlebot hoặc AhrefsBot. Nói cách khác, trang web đang phát hiện một bot cụ thể và chặn tác nhân người dùng tương ứng.
Nếu bạn có thể xem một trang tốt trong trình duyệt thông thường của mình nhưng bị chặn sau khi thay đổi tác nhân User Agent , điều đó có nghĩa là tác nhân User Agent cụ thể mà bạn đã nhập bị chặn.
Bạn có thể chỉ định một tác nhân User Agent cụ thể bằng cách sử dụng Chrome devtools. Một tùy chọn khác là sử dụng tiện ích mở rộng của trình duyệt để thay đổi tác nhân User Agent như tùy chọn này.
Ngoài ra, bạn có thể kiểm tra các tác nhân User Agent bằng lệnh cURL. Đây là cách thực hiện việc này trên Windows:
B1: Nhấn Windows + R để mở hộp “Chạy”.
B2: Nhập “cmd” rồi nhấp vào “đồng ý. ”
B3: Nhập một lệnh cURL như sau:
curl -A “user-agent-name-here” -Lv [URL]curl -A “Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://devweekend.info/robot/)” -Lv https://devweekend.infoLàm thế nào để khắc phục
Thật không may, đây là một lỗi khác mà việc biết cách khắc phục sẽ phụ thuộc vào nơi bạn tìm thấy lỗi.
Nhiều hệ thống khác nhau có thể chặn bot, bao gồm .htaccess, cấu hình máy chủ, tường lửa, CDN, hoặc thậm chí một cái gì đó mà bạn có thể không thấy rằng nhà cung cấp dịch vụ lưu trữ của bạn kiểm soát.
Cách tốt nhất của bạn có thể là liên hệ với nhà cung cấp dịch vụ lưu trữ của bạn hoặc CDN và hỏi họ xem khối này đến từ đâu và bạn có thể giải quyết nó như thế nào.
Ví dụ: đây là hai cách khác nhau để chặn tác nhân người dùng trong .htaccess mà bạn có thể cần tìm.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Googlebot [NC]RewriteRule .* - [F,L]Hoặc là…
BrowserMatchNoCase "Googlebot" bots
Order Allow,Deny
Allow from ALL
Deny from env=bots4. Kiểm tra lỗi từ IP
Nếu bạn đã xác nhận rằng mình không bị robots.txt chặn và loại trừ các lỗi trên, thì có thể lỗi xuất phát từ IP .
Làm thế nào để khắc phục
Lỗi IP là những vấn đề khó theo dõi. Cũng như với các lỗi User Agent, cách tốt nhất của bạn có thể là liên hệ với nhà cung cấp dịch vụ lưu trữ của bạn hoặc CDN và hỏi họ xem lỗi này đến từ đâu và bạn có thể giải quyết nó như thế nào.
Đây là một ví dụ về bạn có thể đang tìm kiếm nằm trong .htaccess:
deny from 123.123.123.123Thông thường, cảnh báo “được lập chỉ mục, mặc dù bị chặn bởi robots.txt” là kết quả từ một khối robots.txt. Hy vọng rằng, hướng dẫn này đã giúp bạn tìm và khắc phục sự cố nếu đó không phải là trường hợp của bạn.
Nguồn: https://ahrefs.com/blog/indexed-though-blocked-by-robots-txt/










